引言
过去这十年,人们无法从数据中获取有价值的信息,这往往被归因于数据量过大。病因是“你的系统太弱了,处理不了这么多数据”,处方是买一些高精尖的技术来处理大规模数据。当然,等大数据部门买好所有的工具和技术,并且迁移到新系统,人们往往发现他们还是很难使用好数据。人们经过认真思考的话,可能也会发现数据大小其实并不是问题的根源。
2023年的世界和最初敲响大数据警钟时的描述可不一样,曾经预言的数据灾难并未出现。数据量的大小可能有些许增长,但是硬件水平明显有更快的增长。供应商们一直在推动硬件的发展,但是从业者已经在思考这和他们面临的现实问题有啥关系。
我是谁?我为啥关心这件事?
近十年来我都是大数据的忠实拥护者。我是Google BigQuery的创始工程师之一,也是团队中唯一一个喜欢公开演讲的工程师,因此我得以有机会去世界各地的大会上解释我们可以如何帮助大家应对即将到来的数据爆炸。我曾经在演讲现场实时演示PB级别的数据查询,以此证明无论您的数据量有多大,我们都能处理,完全没问题。

这张照片是我在2012年西班牙大数据会议上,警告大家海量数据的危险,并且承诺使用我们的技术就不用担心。
接下来的几年中,我花费大量的时间调试客户在使用BigQuery时遇到的问题。我合著了两本书,真正深入到产品的使用中去。在2018年,我转到了产品管理方向,工作内容一方面是和客户交谈(其中很多是全球知名企业),一方面是分析产品的指标。
让我最惊讶的是,大多数使用BigQuery的用户并没有海量的数据。即使是有海量数据的人,也往往只使用了其中的一小部分。当BigQuery产品推出时,对很多人来说它就像一部科幻小说,你没有其他办法能这么快地处理数据。但是,现在这种科幻小说般的情况已经很常见了,更多传统的数据处理方式已经赶上来了。
关于本文
本文想要论述的是大数据时代已经结束。它过去的表现不错,但是现在我们可以停止担心数据量大小的问题,专注于如何利用数据做出更好的决策。我会展示一些图表,我根据记忆手绘了这些图。即使我能访问原始的数据,我也不能分享它们。重要的是曲线的走势,而不是确切的数值。
这些图表背后的数据来源于分析查询日志、事后分析、基准测试的结果(已发布或未发布)、客户支持工单、客户对话、服务日志和博客文章,再加上一些直觉。
幻灯片的惯例
过去十年,每个大数据产品的PPT,都会以类似下图的幻灯片开始:随着时间推移数据量不断增多。
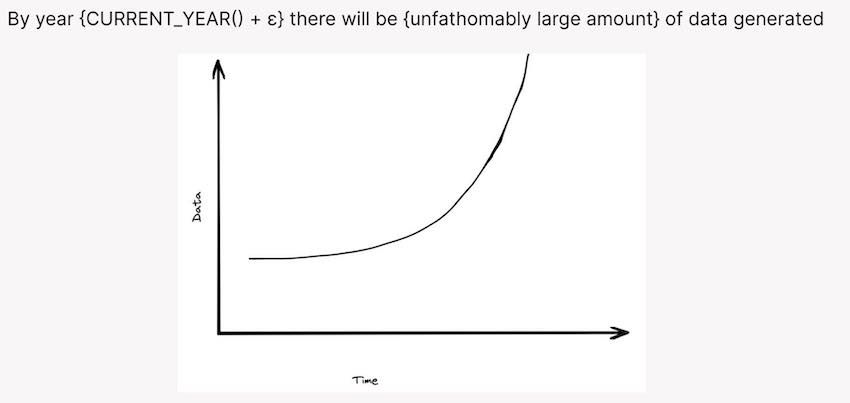
我们在Google使用了一个版本的曲线很多年。当我加入SingleStore时,他们也有类似的自己的版本。我也看到过许多供应商使用的其他类似图标。这些都是“恐吓”幻灯片。大数据来了!你需要买我的产品!
它所传达的是旧的数据处理方式行不通了。数据不断加速产生,会让旧的数据系统陷入沼泽,只要你拥抱新技术,你就可以领先竞争队友一步。
当然,数据生成的量不断增加,并不代表着每个人都需要面对这个问题,数据并不是平均分配给大家的。大多数应用程序不需要处理大量数据。这导致了传统架构的数据管理系统的复兴:SQLite, Postgres, MySQL都在强势增长,而“NoSQL”乃至“NewSQL”系统则是停滞不前。
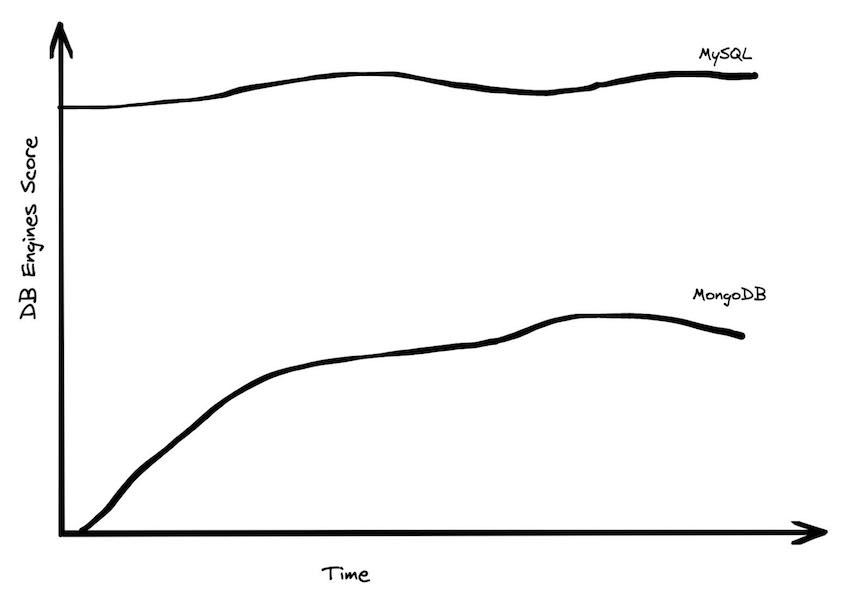
MongoDB是排名最高的NoSQL或者说扩展型数据库,虽然它近些年有过不错的增长,但最近有所下降。而且其实并没有对MySQL或者Postgres这两个单体数据库产生多大影响。如果大数据真的在占领市场,那么这幅图上这些年应该有不同的表现。
当然,在分析系统中这幅图看起来会有所不同。在OLAP中,你会看到一个从本地到云的巨大转变,而在云中没有一个突出的数据分析系统,可以和传统的基于服务器的数据分析系统进行比较。
大部分人没有这么多数据
“大数据来了”这个图表的意思是,用不了多久每个人都会被数据淹没。然而十年过去了,这个未来并没有应验。我们可以通过一些方法来验证这件事:观察数据(定量),询问人们这是否和他们体验一致(定性),以及从第一性原理出发分析(归纳)。
当我在BigQuery工作时,我花费了很多时间研究用户数据量的大小。实际数据很敏感,所以我无法直接分享。然而,我可以说,绝大多数用户的总数据量没有超过1TB。当然,也有一些数据量巨大的客户,但是大多数组织,即使是相当大的企业,数据规模也都有限。
用户数据量的大小遵循幂律分布。最大的用户的存储量是第二大用户的两倍,第二大用户是第一大用户的一半,以此类推。因此,即使有一些用户拥有几百PB的数据,但是这个数据量会急剧下降。有成千上万的用户每月支付不到10美元的存储费用,相当于0.5TB。在那些频繁使用该服务的用户中,数据存储量的中位数远低于100GB。
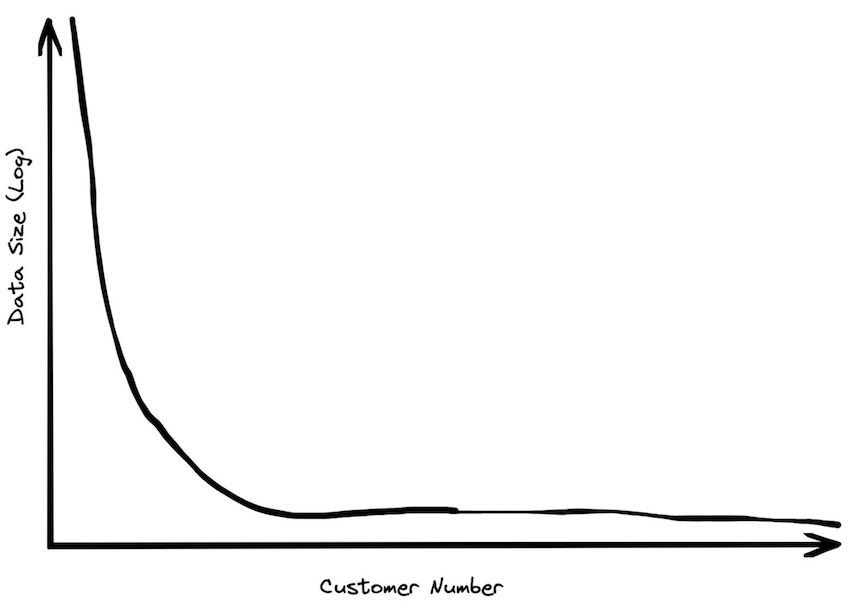
我们在与行业分析师(例如Gartner、Forrester等)交流时,发现了其他的证据。我们会炫耀我们处理大数据的能力,但是他们会耸耸肩。“这确实不错,”他们说,“但是绝大多数企业的数据仓库都小于1TB”。在与相关行业人士沟通时,普遍的反馈是100GB是数据仓库正确的量级,这也是我们在基准测试中的主要关注点。
我们的一位投资者决定弄清楚分析型数据的量级,他对自己的投资组合公司进行了调查,其中一些已经退出了私有所有权阶段(已经成功IPO或者被其他公司收购)。这些公司都是科技公司,更有可能产生大量的数据。他发现他投资的最大的B2B公司大约有1TB的数据,而最大的B2C公司大约有10TB的数据。但是大多数公司拥有的数据远远不到这个规模。
为了理解为什么海量数据很少见,可以考虑一下数据从哪产生。假设您拥有一家中等规模的公司,有1000个客户。假设您的每个客户每天都下单,每个订单有100件商品。这个频率已经很高了,但是每天能产生的数据不足1MB。三年后,您会有大概1GB数据。几千年后,您会有1TB数据。
或者,假设您的营销数据库中有一百万潜在用户,并且您在运营着数十个营销活动。您的客户表大概率也不会超过1GB,跟踪每个潜在用户在每个营销活动中的行为也不过几GB。在合理扩展的假设下,我们很难看到这会导致海量数据的产生。
举个具体的例子,我曾在2020年至2022年期间在SingleStore工作,那是它是一家增长迅速的E轮公司,拥有不菲的收入和独角兽估值。如果将我们的财务数据仓库、客户数据、营销活动跟踪和服务日志加起来,可能也只有几GB。无论怎么想,它也成不了大数据。
存算分离中的存储偏差
存算分离是现代云数据平台的一种架构,这意味着用户不再和单一的要素进行绑定。和数据量相比,这件事情可能是过去20年来数据架构中最重要的改变。相比于什么都不分享的架构,分享硬盘的架构可以让你独立扩展存储或者计算资源。随着像S3和GCS这样的可扩展并且足够快的对象存储的兴起,您可以放宽对于数据库构建的很多约束条件。
实际上,数据量增长的速度远超过计算量。尽管存算分离的好处听起来就像是你可以随意扩展其中一个维度,但是这两个轴并不是等价的。对这点的误解导致了很多关于大数据的讨论,因为处理大量计算任务不同于处理大量存储数据。下面讨论一下为什么会这样。
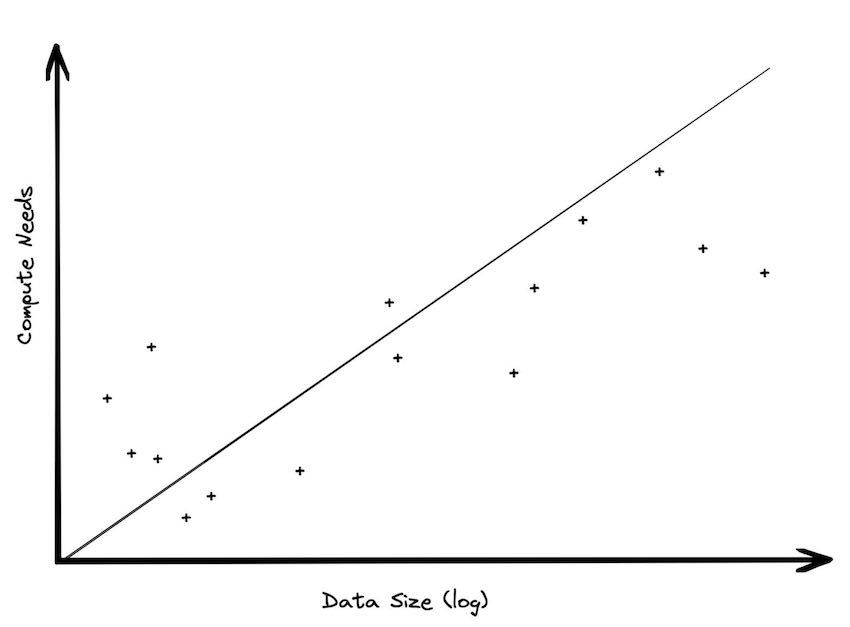
所有大数据集都是随着时间产生的,时间总是数据集的一个维度。每天都有新的订单,新的出租车行程,新的日志记录,新的游戏对弈。如果一个企业是静态的,既不增长也不萎缩,那么数据将会随着时间线性增加。这对于分析需求意味着什么?显然,除非您决定修剪数据(稍微详细讨论),否则数据存储需求是线性增长的。但是计算需求可能不会随着时间有很大的变化。大多数分析是基于近期数据进行的。扫描旧数据成本很高,这一点不会改变,那么为什么要一遍一遍花钱重复读取它呢?当然,您可能是想归档好数据,以防万一将来有所需求,但是将重要数据聚合出来并保存其实也很简单。
很多时候,当数据仓库的用户从原来的环境迁移到有存算分离能力的环境后,他们的存储用量会大幅提高,但他们的计算需求往往不会有多大变化。在BigQuery时,我们有一个用户是世界最大的零售商。他们有一个接近100TB的本地数据仓库,当他们迁移到云上之后,他们的存储量增长到了30PB,增加了300倍。如果他们的计算需求也按相似倍数增长的话,那么他们将在数据分析上花费数十亿美元。当然,他们只花了很少一部分。
与计算需求相比的存储偏差,对系统架构产生了实际的影响。这意味着如果您使用了可扩展的对象存储,那么您需要的计算量比预期会少得多,甚至您根本不需要使用分布式处理。
数据工作负载比总的数据量要小
进行数据分析时数据量的大小肯定比您想的要小得多。比如通常使用聚合的数据来搭建Dashborad,人们往往查看过去一小时、一天或一周的数据。更小的表查询的更频繁,而巨大的表往往是选择性的查询。
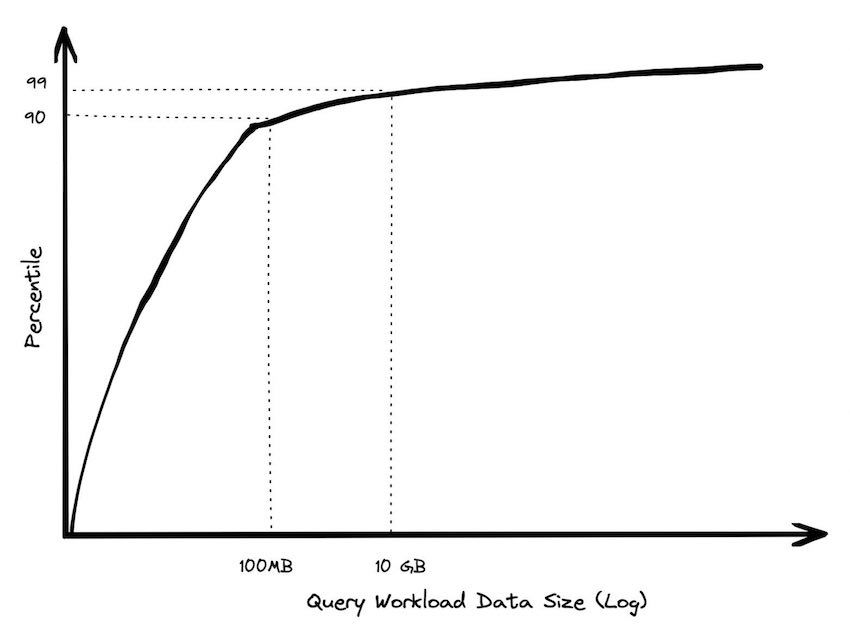
几年前,我对BigQuery的查询进行过分析,研究了每年花费超过1000美元的用户。90%的查询处理的数据量不到100MB。我以多种不同的切片方式来分析,确保它不是某些运行了大量查询的用户导致的有偏结果。我也剔除了元数据相关的查询,这只是BigQuery中不需要读取大量数据的查询中的一小部分。必须上升到前99%,您才能进入到GB的级别,只有极少数的查询运行在TB级别。
拥有海量数据的用户几乎从不查询海量数据。
拥有中等数据量的用户可能会进行一些大查询,但是拥有海量数据的用户几乎从不进行大查询。当他们这样做时,通常是为了准备一份报告,在这种情况下查询性能并不是重点。一个社交媒体公司会在周末跑一些分析任务,方便准备周一早上的高管会议。这些查询很大,但是只占他们在一周内运行的数十万个查询的一小部分。
即使在查询大数据表时,你也很少需要处理大量的数据。现代的分析型数据库可以通过列投影来读取字段的子集,并且通过分区剪枝来读取有限的日期范围。它们通常还能够通过聚类或自动微分区,来进一步利用数据中的局部性来进行分段消除。还有一些其他技巧,比如说在压缩数据上运算、投影和谓词下推等,可以减少查询时的IO消耗。更少的IO意味着需要更少的运算,进一步意味着更少的延迟和花费。
有很强烈的经济压力促使人们减少处理时的数据量。即使您可以扩展存储并且快速处理大量数据,并不意味着可以不计成本这样做。使用1000个节点来计算结果的花销巨大。我在演讲中实时展示的PB量级的BigQuery查询,按零售价算需要花费5000美元。很少有人愿意承担这么昂贵的操作。
需要注意的是,即使您没有使用按照扫描数据量计费的定价产品,省钱仍然是推动少处理数据的重要原因。以Snowflake实例为例,如果您的查询更小,那您就可以使用一个更低配的机器实例,并且支付更少的费用。您的查询速度会更快,您能够同时跑更多的查询,并且一般来说花费会更少。
大多数数据很少被查询
被处理的数据中24小时以内的数据占绝大多数。一周之前的数据比起最近一天的数据,被查询到的概率降低了20倍。一个月之前的数据往往就是存在那了。历史数据很少被查询到,除非有人在查询一份罕见的报告。
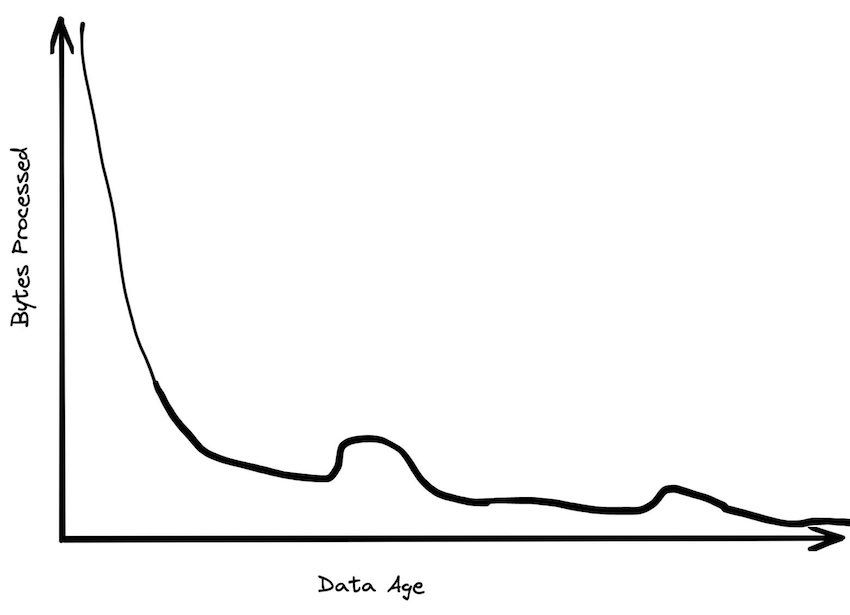
数据存储的时间曲线平缓的多。虽然有很多数据很快就被丢弃了,但是大量的数据就是被追加到表的末尾。最近一年的数据可能只占全部数据量的30%,但是占据了99%的数据访问量。最近一个月可能只占据全部数据量的5%,但是占据了80%的数据访问量。
数据的这种静止属性意味着管理数据集比您想象的更容易。如果您有一个存储了10年的,拥有1PB数据量的表,你可能很少访问当天以前的数据,而这些数据压缩之后可能只有不到50GB。
大数据的战线节节败退
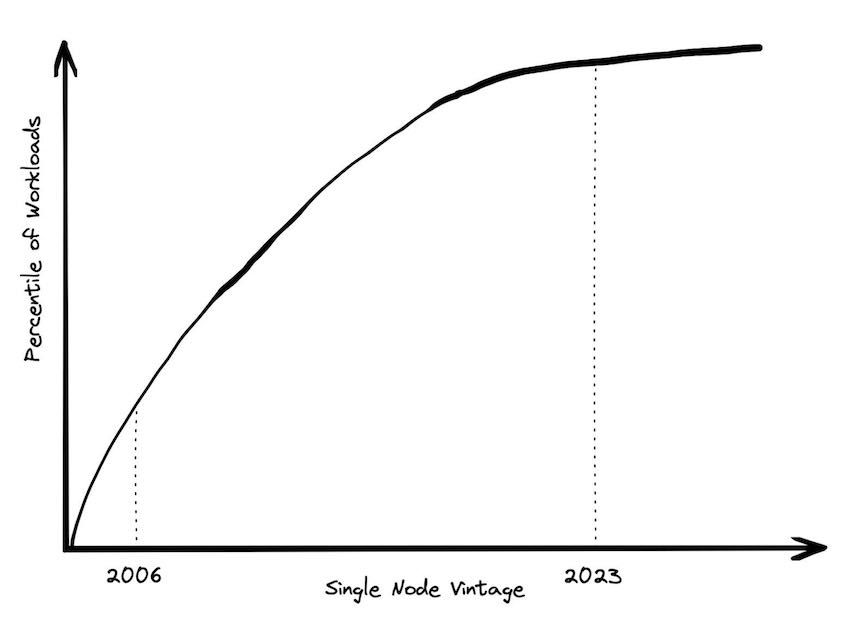
大数据的一种定义是“无法在单机上处理的数据”。按照这个定义,符合条件的数据工作负载每年都在下降。
2004年谷歌发布MapReduce论文时,数据工作负载无法在一台单机上处理是很普遍的。扩展的成本非常昂贵。2006年亚马逊推出了EC2,当时你只能用一种规格的实例,单core和2GB内存。有很多工作负载超过了这台机器的能力。
然后如今,亚马逊的标准实例为64core和256GB内存。在内存上是两个数量级的提升。如果您愿意为内存多花一些钱,购买内存优化的实例,您可以获得另外两个数量级的内存提升。有多少工作负载是超过445core和24TB内存的呢?
以前大型机器确实很贵。然而现在在云服务上,使用整个服务器的虚拟机只比使用1/8个服务器的虚拟机贵8倍。成本随着计算能力提升线性增长,直到非常大的尺度上。事实上,如果你看看最初Dremel论文中使用3000个并行节点完成的基准测试,你今天可以在单个节点上获得类似的性能(而且还在不断提升)。
数据是一种负债
大数据的另外一个定义是“当保存数据的成本低于弄清楚要删除哪些数据的成本”。我更喜欢整个定义,因为它解释了为什么我们最终会有大数据。并不是因为他们需要数据,而是因为他们没有删除数据。如果你考虑一些组织的数据胡,它们完全符合这个标准:巨大、杂乱无章的沼泽地,没有人真的知道它们里面都有什么,清理掉它们是否安全。
保存数据的成本不仅仅是存储物理字节的成本。在像GDPR和CCPA这样的法规下,你需要跟踪某些类型数据的所有使用情况。某些数据需要在一定的时间内删除。如果你的数据湖中的某个parquet文件中的电话号码数据一直保留了下来,那么你可能已经违法了。
在合规以外,数据也可能成为针对你的诉讼的证据。就像很多组织强制要求保留电子邮件来避免担责一样,你的数据仓库中的数据也可能被用来指控你。如果你五年前的日志记录,可以显示你的系统存在安全漏洞或者未满足SLA,那么保留这些日志数据可能会增加你的法律风险。我道听途说过一个故事,曾经有一个公司为了避免在法律发现过程中被使用,隐瞒了自己的数据分析能力。
代码在缺少主动维护时往往会腐烂,数据也有同样的问题。人们会忘记确切字段的宝贵含义,或者数据问题可能已经被遗忘。比如说,可能有一个短暂的数据bug将每个客户ID置为null,或者有一个大规模的欺诈交易使2017年Q3的数据好看很多。通过从历史时间段中提取数据的业务逻辑会越来越复杂。例如,可能有一个规则:“如果日期早于2019,则使用revenue字段,2019年到2021年使用revenue_usd字段,2022年以后需要使用revenue_usd_audited字段”。保存数据的时间越长,就越难跟踪维护这些特殊情况。并且并非所有情况都可以简单的处理并解决,尤其是数据缺失时。
如果你一直保留着旧数据,理解为什么要保留它是很重要的。你是否一直在查询同样的问题?如果是这样,那么只保留聚合结果对于存储和计算来说都更划算。你保留数据是为了不时之需吗?你认为会有新的查询需求被提出来吗?如果是的话,这些问题有多重要呢?你真的需要保留数据吗?还是说你是一个数据囤积者?这些问题都很重要,特别是你想弄清楚保存数据的真正成本时。
你在大数据的前1%中吗?
大数据确实是真实存在的,但是大部分人并不需要为此担心。以下是一些问题,可以帮助你判断自己是不是那前1%:
你真的产生了海量数据吗?
如果是,你是否真的需要一次性用到海量数据?
如果是,这些数据真的不能被单机处理吗?
如果是,你确定自己不是一个数据囤积者吗?
如果是,你确定不能把数据更好的进行总结吗?
如果你对上述中的任意一个问题的回答是否定的,那么你可能需要使用新一代的数据处理工具,帮你处理现实大小的数据量,而不是一些人试图恐吓你让你焦虑的数据量。